
Demo: OpenAI Realtime API Voice that sounds like Hulk (Pitch Shifted < 1.0)
Pitch Shifting with Realtime AI APIs
In this blog post, we will learn how to create cartoon-like realtime AI voices with pitch shifting on ESP32 Arduino.
What is Pitch Shifting?
Pitch shifting is a technique that allows you to change the pitch of a sound without changing the speed. This is useful for creating cartoon-like AI voices. For example, if you want to create a cartoon-like AI voice that sounds like a child, you can use pitch shifting to increase the pitch of the voice. And you can deepen a voice by lowering its pitch, to make it sound like an AI Hulk or an AI version of Azog from Lord Of The Rings.
Why Pitch Shifting?
When I spoke to a few doctors in the UK about using Elato as a comfort tool in hospitals, they were not excited about the Adult voices that were available then on OpenAI and Azure (except for Gisela). They were more excited about the child voices to lessen children’s anxiety.
One of our customers also had a similar request. In his own words,
OpenAI Voices are not well suited for a small toys. The ultimate goal is to build a toy for my 10-year-old daughter that can answer simple questions and tell fairy tales on request.
His Furby-like setup was an incredible idea. I was excited to help him with it and add this as a feature to our Elato devices and dev kits. His current setup with an ESP32 XIAO:

How to create cartoon-like realtime AI voices with pitch shifting on ESP32 Arduino?
In his repo arduino-audio-tools, Phil Schatzmann has laid the ground work for pitch shifting on an ESP32. Linked here: arduino-audio-tools Pitch shifting Wiki.
We wrap these methods with helper functions to make this easier to use when outputting audio to a speaker. Previously, when we wanted to output AI audio from our websocket onto the I2S speaker. We used the following setup:
Our pipeline was:
OpusDecoder → BufferPrint → audioBuffer → QueueStream → VolumeStream → I2SStreamAnd our stream setup:
VolumeStream volume(i2s); //access from audioStreamTask only
QueueStream<uint8_t> queue(audioBuffer); //access from audioStreamTask only
StreamCopy copier(volume, queue);
AudioInfo info(SAMPLE_RATE, CHANNELS, BITS_PER_SAMPLE);To implement pitch shifting, we need to add the following to our setup:
OpusDecoder → BufferPrint → audioBuffer → QueueStream → PITCH_SHIFT_OUTPUT → VolumeStream → I2SStreamAnd our new stream setup (with pitch shift):
// NEW for pitch shift (lossy for pitch factor of 1.0)
PitchShiftFixedOutput pitchShift(i2s);
VolumeStream volumePitch(pitchShift); //access from audioStreamTask only
StreamCopy pitchCopier(volumePitch, queue);In our websocketEvent callback function, when we fetch pitch factor information from the server, we can use it to set the pitch factor of the pitch shift output like so. (Note: We only initialize the pitch shift output if the pitch factor is not 1.0)
// Only initialize pitch shift if needed
if (currentPitchFactor != 1.0f) {
auto pcfg = pitchShift.defaultConfig();
pcfg.copyFrom(info);
pcfg.pitch_shift = currentPitchFactor;
pcfg.buffer_size = 512;
pitchShift.begin(pcfg);
}For the pitch shift implementation, we use a granular synthesis approach. This is a technique that allows you to create a sound by breaking it down into small pieces and then reassembling them in a new way using two buffers (“grains”) of 1024 samples each.
Thank you to Roman Lut for the help with this implementation. You can find the PitchShift.cpp and PitchShift.h helpers with the implementation PR linked here: PR #1.
How to use the pitch shift output?
We can use the pitch shift output just like we would use the volume output. You can set this value on the UI when you clone the repo and set up your NextJS frontend.
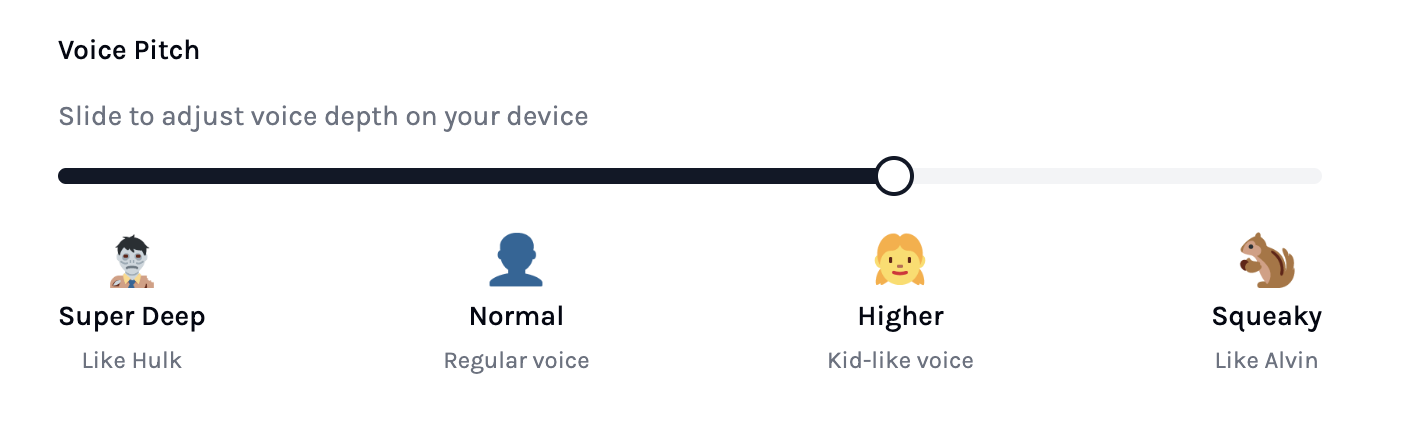
This gets picked up on the Deno server and sent to the ESP32 via websocket.
In Conclusion
We have now learned how to create cartoon-like realtime AI voices with pitch shifting on ESP32 Arduino. This is a powerful technique that can be used to create a wide range of AI voices.
You can find the full code for this project here: ElatoAI.
Thank you for reading!